
Qu'est-ce que la pseudonymisation des données ?
La pseudonymisation est une méthode de sécurisation des données qui vise à rendre impossible l'association directe des informations à une personne spécifique, à moins de disposer de données supplémentaires. Concrètement, cette technique consiste à substituer les identifiants personnels (comme le nom, prénom, adresse email, numéro de téléphone, etc.) par des pseudonymes.
Quel est l'objectif de la pseudonymisation ?
La pseudonymisation poursuit un double objectif : améliorer la protection des données et diminuer les risques en matière de confidentialité, tout en permettant aux entreprises de traiter ces informations à des fins légitimes telles que l'analyse ou le partage.
Dans quels cas la pseudonymisation est-elle recommandée ?
La pseudonymisation permet de sécuriser les données tout en conservant leur utilité complète. Elle contribue également à respecter le principe de protection des données dès la conception.
Elle est particulièrement indiquée dans le cadre de traitements de données à des fins de recherche scientifique, lorsque des informations précises au niveau individuel sont requises, mais que les données directement identifiantes ne sont pas indispensables à la réalisation de cette recherche.
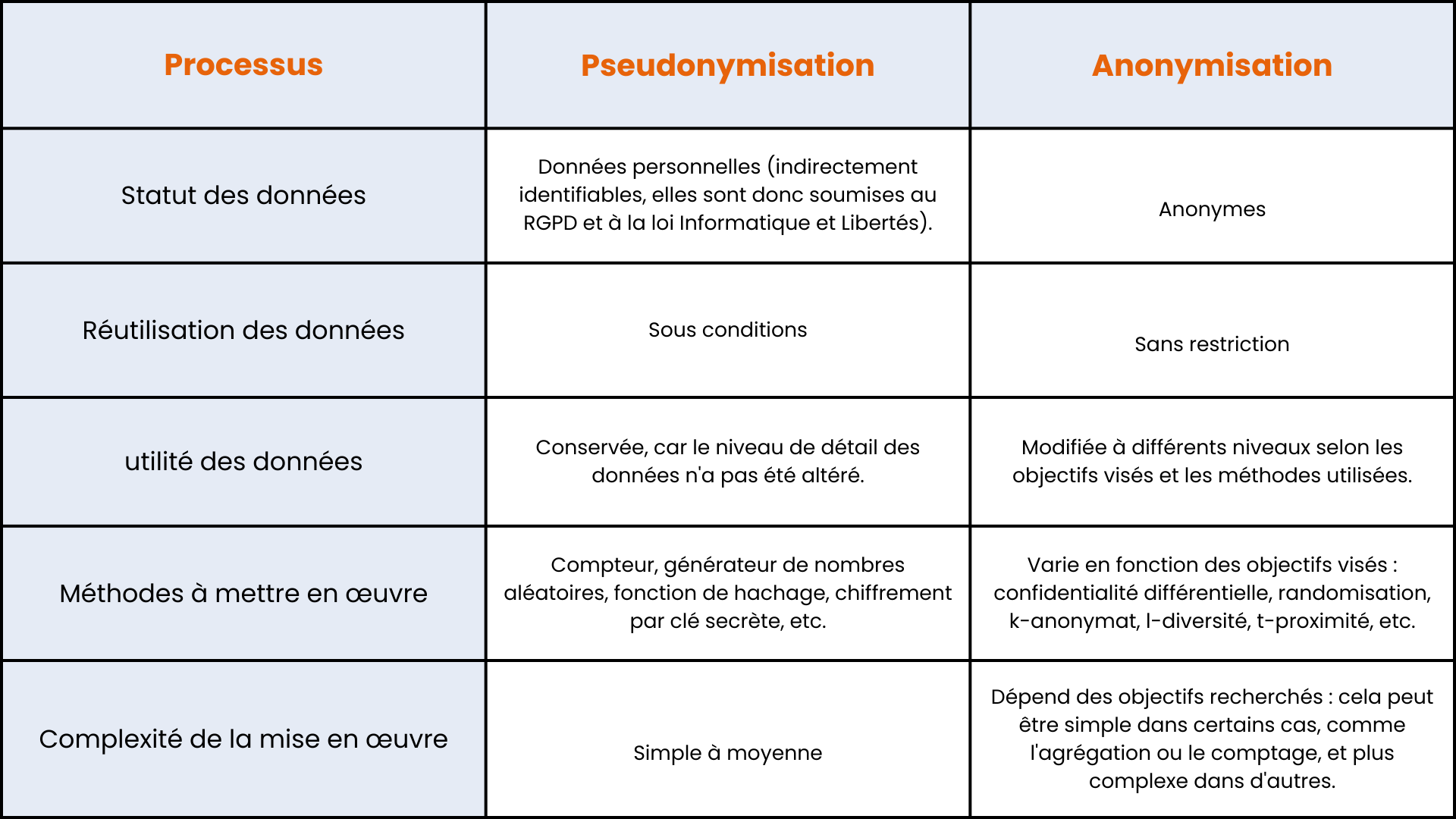
Quelle est la différence entre pseudonymisation et anonymisation des données ?
L'anonymisation et la pseudonymisation sont deux mesures similaires visant à protéger la confidentialité des données, mais elles diffèrent par leur niveau de protection.
- L'anonymisation supprime toutes les informations identifiantes d'un ensemble de données, rendant impossible l'identification directe ou indirecte d'une personne.
- En revanche, la pseudonymisation remplace ces informations par des pseudonymes, qui peuvent être réattribués à l'individu à l'aide d'une clé de pseudonymisation.
4. Quels sont les techniques de pseudonymisation ?
Différentes techniques de pseudonymisation peuvent être employées. Certaines se basent sur des méthodes simples comme la création de pseudonymes via un compteur ou un générateur de nombres aléatoires, tandis que d'autres utilisent des techniques cryptographiques, telles que le chiffrement par clé secrète ou les fonctions de hachage.
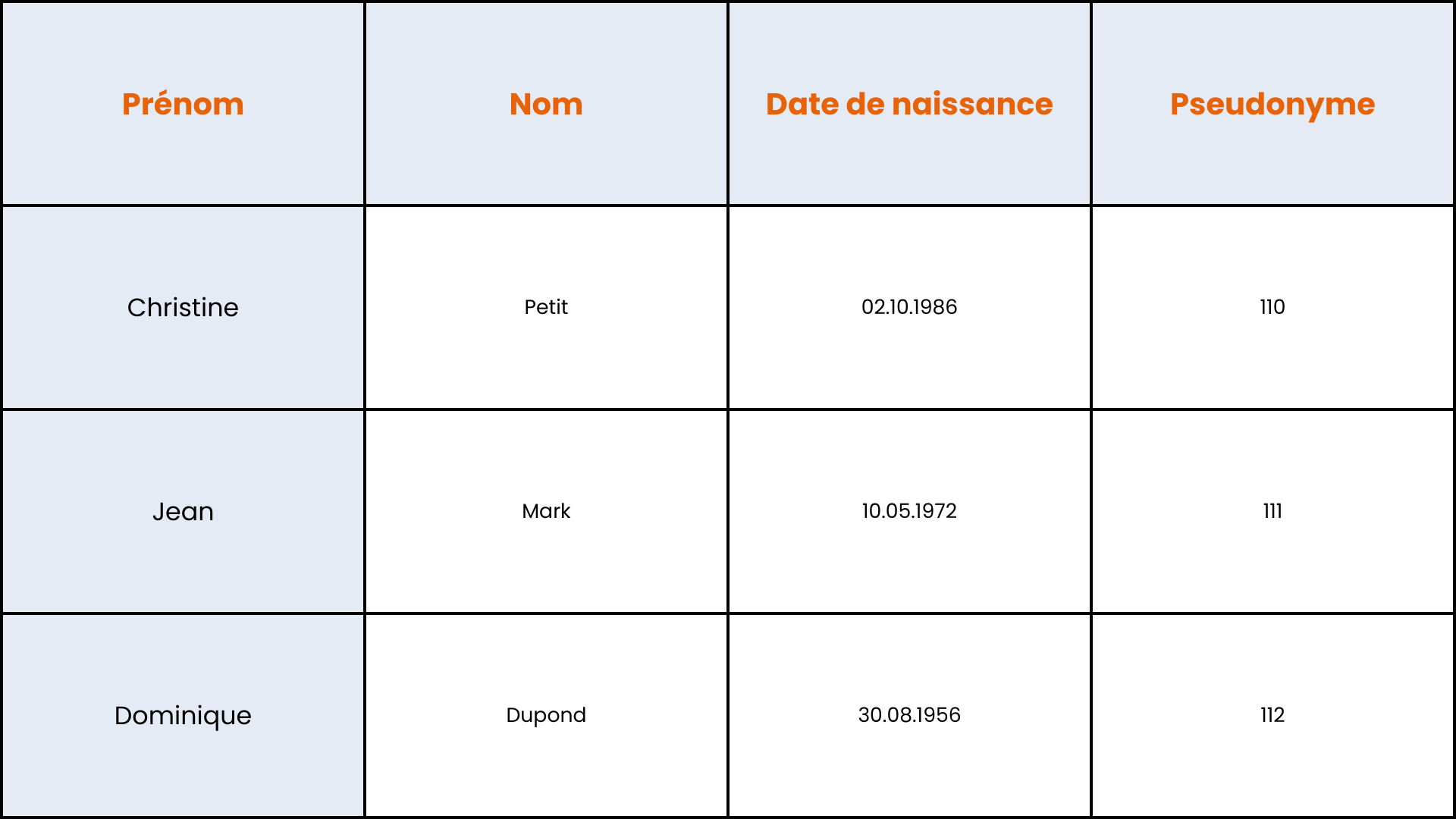
Compteur
Cette méthode consiste à remplacer un attribut ou un ensemble d’attributs identifiants par un nombre généré par un compteur. Une valeur initiale est définie, puis elle est incrémentée pour chaque nouvel enregistrement. Il est crucial que les valeurs générées par le compteur soient uniques, afin d’éviter toute ambiguïté ou qu’un même pseudonyme soit attribué à deux enregistrements distincts. L'avantage du compteur réside dans sa simplicité, ce qui en fait une option idéale pour des ensembles de données de petite taille et sans complexité. Cependant, pour des bases de données plus volumineuses et sophistiquées, cette approche peut poser des difficultés en termes de mise en œuvre et de scalabilité, car il est nécessaire de stocker une table de correspondance complète reliant les attributs aux pseudonymes.
Pseudonymisation via un compteur :
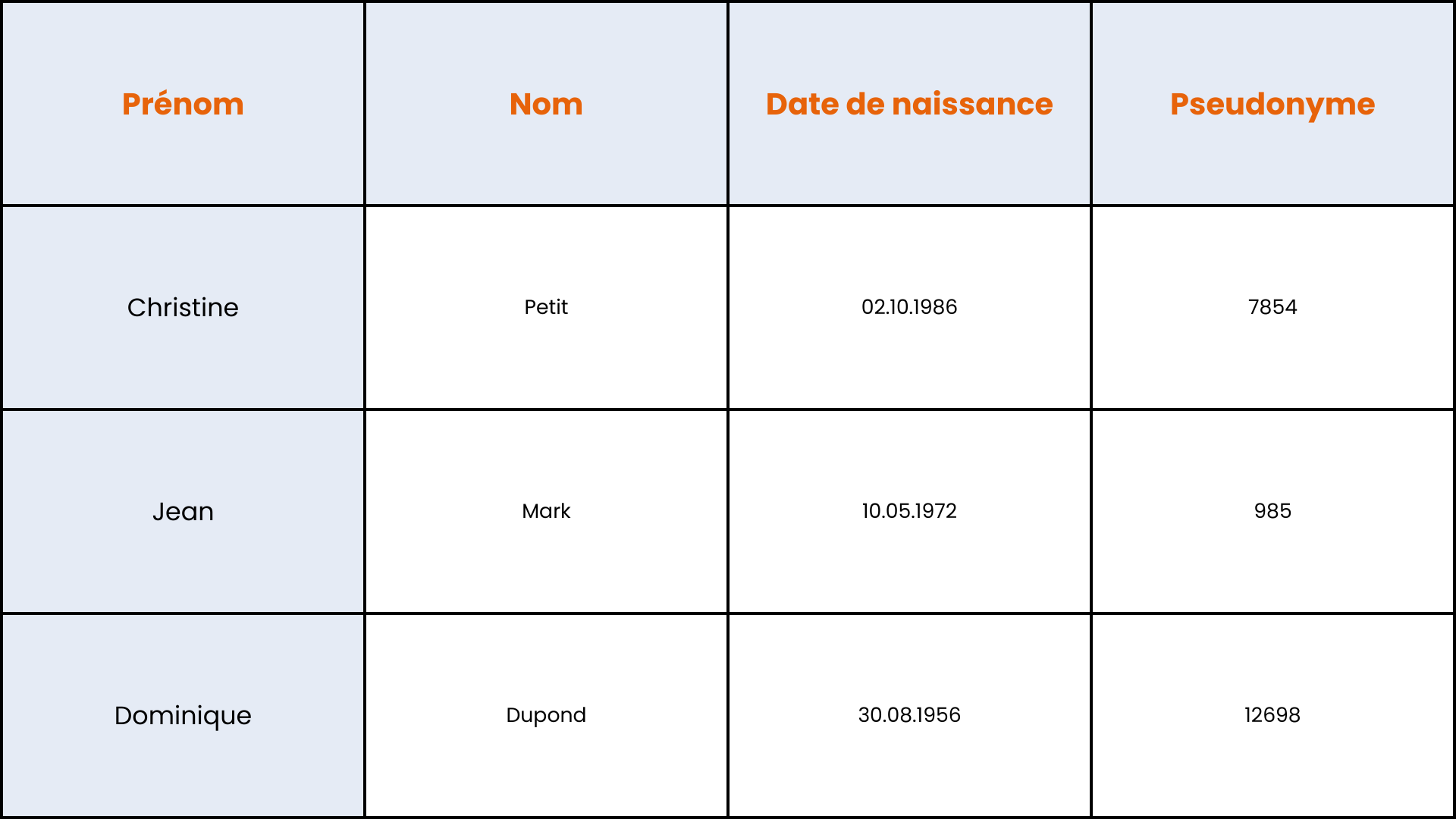
Générateur de nombres aléatoires
Cette technique consiste à générer des valeurs ayant toutes la même probabilité d’être choisies dans l’ensemble des possibilités. Elle permet de créer des pseudonymes aléatoires, c’est-à-dire des valeurs imprévisibles et indépendantes des données personnelles d'origine. Contrairement à la méthode du compteur, où les valeurs sont attribuées de manière séquentielle, ici chaque identifiant reçoit une valeur aléatoire, ce qui empêche de déduire un ordre dans les données.
Cependant, il est important de veiller à éviter les collisions (l’attribution du même pseudonyme à plusieurs enregistrements). Cela peut être évité en spécifiant l’espace mathématique pour les nombres aléatoires ou en mettant en place un tirage sans remise, notamment lorsque différents sites traitent des sous-échantillons.
Pseudonymisation via un générateur de nombres aléatoires
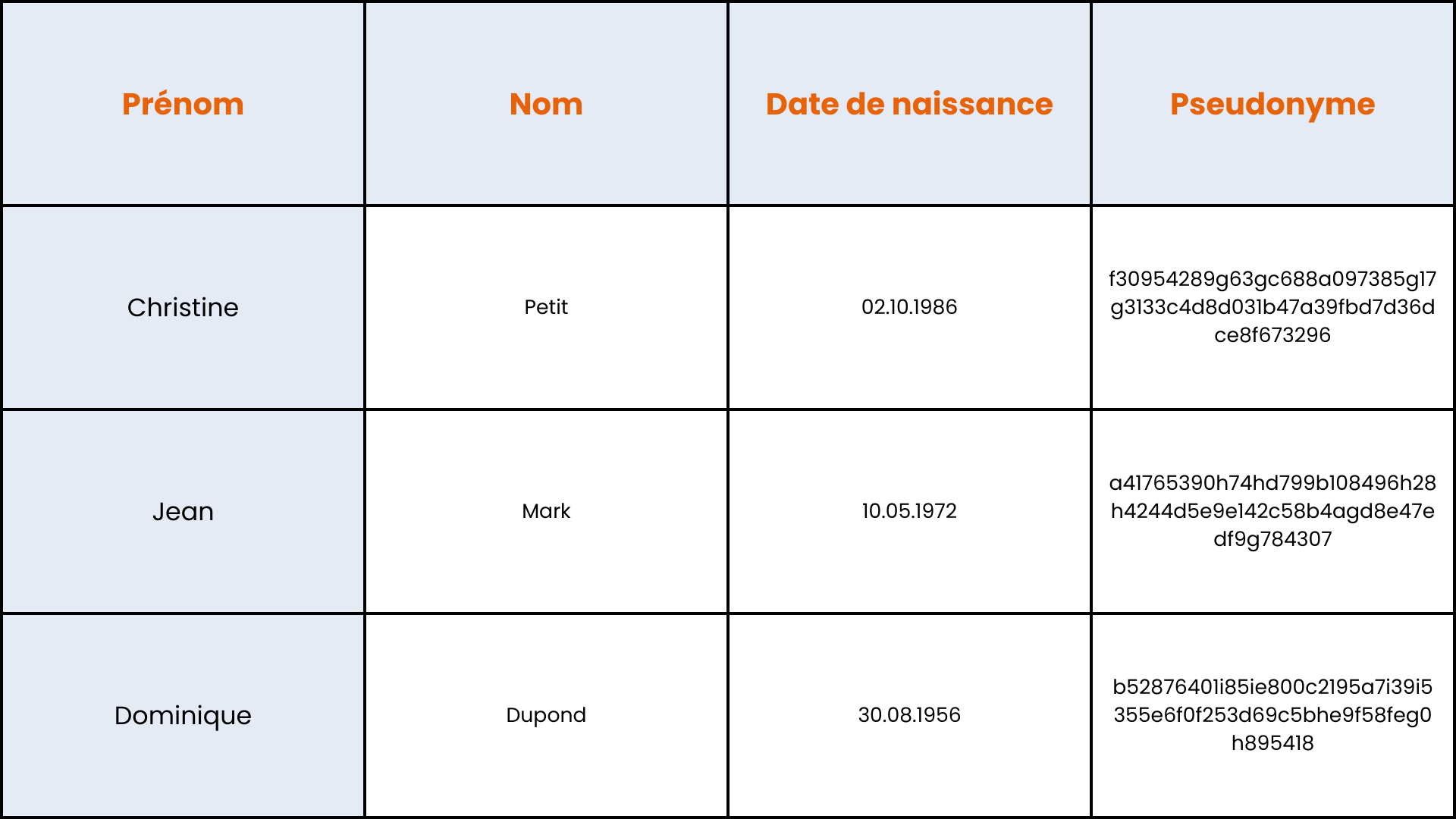
Chiffrement à clé secrète
Cette méthode consiste à chiffrer les données identifiantes afin de les rendre illisibles. Le détenteur de la clé secrète peut réidentifier les individus en déchiffrant les données, puisque celles-ci, bien que chiffrées, restent présentes dans le fichier. Il est donc crucial de stocker la clé en toute sécurité et de la rendre accessible uniquement aux personnes autorisées. De plus, il est essentiel d’utiliser une méthode de chiffrement conforme aux standards actuels.
Bien que les méthodes de chiffrement déterministes, qui produisent toujours le même pseudonyme pour une même donnée d’entrée, soient les plus courantes, les méthodes de chiffrement probabilistes peuvent aussi être utilisées. Ces dernières introduisent une part d’aléatoire dans le résultat, ce qui brise les corrélations entre les enregistrements associés à un même individu.
Pseudonymisation via chiffrement à clé secrète
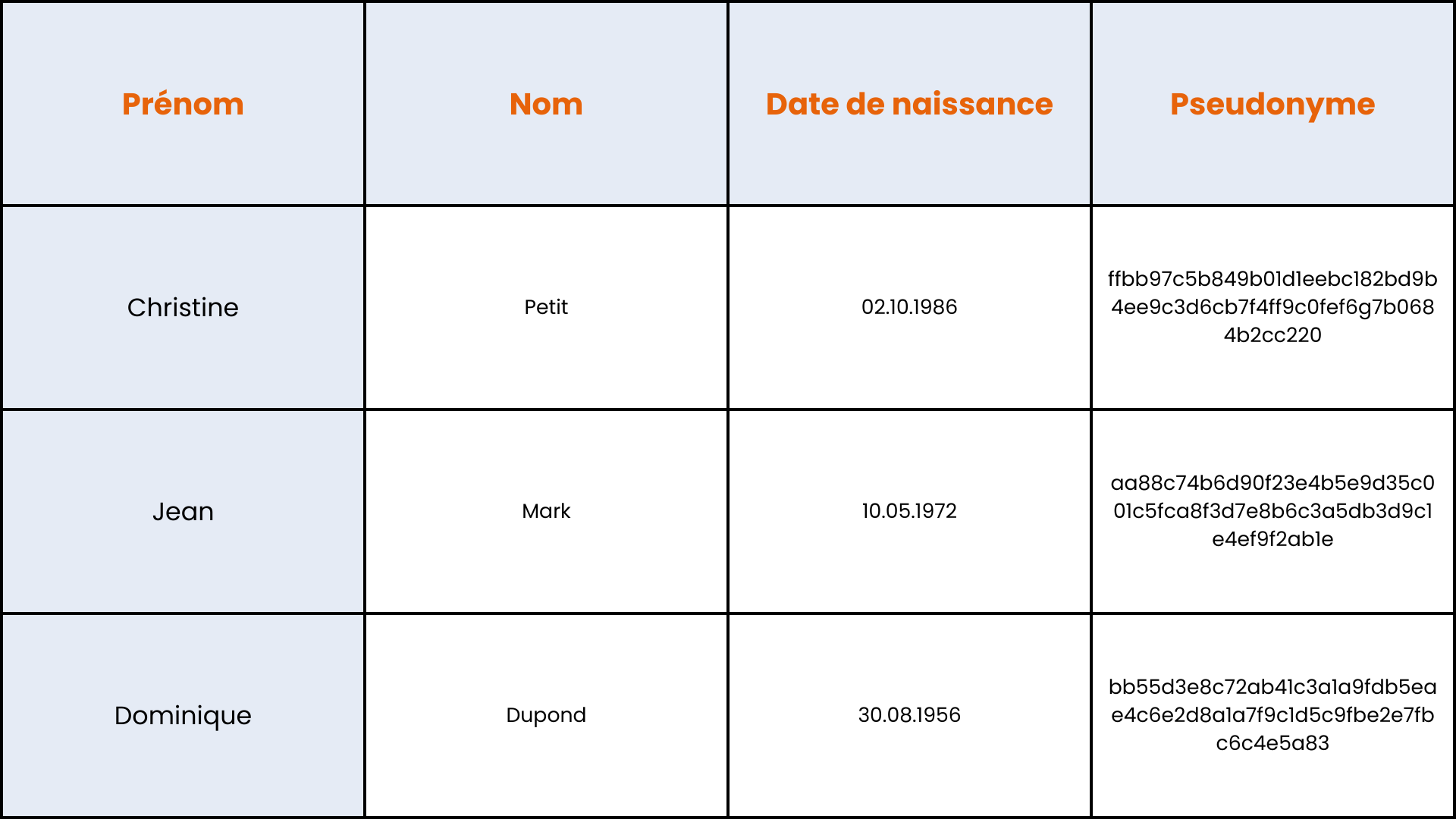
Fonction de hachage
Une fonction de hachage produit un résultat de taille fixe, quel que soit le volume de données en entrée (qui peut être un attribut unique ou un ensemble d'attributs), et elle n’est pas conçue pour être inversée. Contrairement au chiffrement, il n’est donc pas possible de récupérer facilement les données en clair.
Cependant, les fonctions de hachage sont publiques, ce qui signifie que tout le monde utilise les mêmes algorithmes, et elles sont généralement optimisées pour un calcul rapide. Cela les rend vulnérables aux attaques par force brute, où l'on tente toutes les entrées possibles pour créer des tables de correspondance. Des tables pré-calculées, connues sous le nom de "rainbow tables", peuvent également être utilisées pour faciliter la reconstitution massive des valeurs de hachage.
Pour atténuer le risque de reconstitution des valeurs d'entrée, il est crucial d'utiliser une fonction de hachage avec « salage » (ajout d'une valeur aléatoire et secrète, appelée « sel », à l’attribut haché) ou d’intégrer une clé secrète. Idéalement, on devrait recourir à une fonction de hachage de la sous-famille des « fonctions de dérivation de clé », qui sont spécialement conçues pour intégrer une clé secrète de manière optimale.
Pseudonymisation par utilisation d’une fonction de hachage
Substitution, généralisation et floutage
Certaines techniques, connues sous les noms de substitution, généralisation ou floutage, sont couramment utilisées dans le cadre de recherches scientifiques. Elles consistent à remplacer les données directement identifiantes par d'autres données sélectionnées de manière aléatoire ou semi-aléatoire. Les chercheurs en sciences humaines et sociales utilisent souvent ces méthodes pour attribuer des identités fictives « similaires » d’un point de vue socio-culturel aux participants de leurs études (choix des prénoms, profession, employeur, lieu de résidence, etc.).
Les techniques d'identification automatique des données personnelles dans des documents textuels (comme les comptes rendus médicaux ou les décisions de justice) peuvent également proposer une forme de substitution. Cela présente l'avantage de rendre moins perceptibles les erreurs de détection qui peuvent survenir avec des méthodes automatisées.
Cependant, qu'il s'agisse de recherche qualitative ou quantitative, cette pratique, bien qu'étant un premier niveau de protection, ne constitue pas une technique de pseudonymisation au sens du RGPD.
Quelle technique de pseudonymisation choisir ?
Le choix de la technique de pseudonymisation adéquate repose sur deux principaux facteurs : le niveau de protection nécessaire et l'utilité des données pseudonymisées pour la recherche envisagée. Il est donc essentiel de trouver un équilibre entre ces deux aspects en se posant les bonnes questions concernant le traitement proposé. Quelles informations sont réellement indispensables ? Est-il nécessaire de relier les données d’un même individu ? La structure des données doit-elle être préservée ? Etc.
Quel que soit le procédé de pseudonymisation choisi, les informations permettant de lier les pseudonymes aux données directement identifiantes sont particulièrement sensibles. Il est crucial de garantir la confidentialité de ces éléments (table de correspondance, « sel », clé de chiffrement, etc.) à travers des mesures techniques et organisationnelles appropriées. Ces informations doivent être accessibles uniquement par des personnes autorisées et dans des conditions définies à l’avance.